CS 343 Concurrency
1. Advanced control flow
Labelled break
Normal and labelled break are a goto with limitations:
- cannot loop, only forward branching
- cannot branch into control structure, only out
Situations where dynamic allocation (heap) is necessary
- variable’s storage outlives its allocation block
- amount of data read is unknown
- array of objects must be initialized via constructor (instead of default constructor)
- large local variables on small stack
2. Dynamic multi-level exit
Nonlocal transfer
Label variable L containing a tuple:
- pointer to block activation on the stack
- transfer point within the block
Nonlocal transfer via goto L
- direct control flow to specified activation stack
- go to transfer point (label) within routine
Causes termination of stack block
jmp_buf, setjmp, and longjmp in C
Exception terminology
source execution: execution raising the exception
faulting execution: execution changing control flow due to raised exception (propagation)
local exception: source = faulting
nonlocal exception: source ≠ faulting
termination: control cannot return to raise point
- all blocks on faulting stack from the raise block to the guarded block handling the exception are terminated – stack unwinding
resumption: control returns to raise point – no stack unwinding
Static/dynamic call/return
- sequel: static call, static return
- control returns to the end of the block in which the sequel is declared
- routine: static call, dynamic return
- termination: dynamic call, static return
- unknown handler -> dynamic raise
- when handler returns, stack is unwound -> static return
- resumption: dynamic call, dynamic return
- unknown handler -> dynamic raise
- handler return is dynamic -> control returns to location in faulting execution (for nonlocal resume, return to beginning of _Enable)
Raising
_Throw or _Resume
Nonlocal/concurrent raise restricted to resumption since raising execution is unware of faulting execution state. Don’t want to force stack unwinding on the faulting execution, and resumption allows flexibility.
3. Coroutine
Share a thread deterministically, so is not concurrency.
semi coroutine: activates member routine that activated it
full coroutine: has resume cycle
On resume, this must be a non-terminated coroutine
On deleting a non-terminated coroutine, its stack is unwound and destructors called.
Full coroutine
3 phases:
- start cycle
- execute cycle
- stop cycle
Special case for starting cycle for mutually recursive references x(y), y(x):
x, y(x);
x.partner(y);
Coroutine languages
stackless coroutine: use caller’s stack and fixed-size local state
- can’t call other routine and suspend in other routine
- generators/iterators
stackful coroutine: separate stack and fixed-size local state
4. More exceptions
5. Concurrency
Speedup
speedup SC = T1/TC where Tn is execution time with n CPUs (n = 1 is sequential execution)
SC = k means k times speedup
Types of speedup: super linear (unlikely), linear (ideal), sub linear (common), non linear (common)
Amdahl’s law: SC = 1 / ((1 - P) + P / C). Concurrent section is P, sequential section is 1 - P. C is #CPUs.
Synchronization and communication
busy wait: loop waiting for an event among threads
atomic operation: not divisible
critical section: a group of instructions that must be performed atomically
mutual exclusion: prevent simultaneous execution of a critical section by multiple threads
Software solutions to mutual exclusion
RW-safe: mutex algorithm works if simultaneous writes scramble bits and simultaneous read/write reads flickering bits
Dekker is not RW-safe because it has simultaneous R/W
- unbounded overtaking because race loser retracts intent
Hesseklink is RW-safe version of Dekker
Peterson is RW-unsafe requiring atomic read/write
- bounded overtaking because race loser does not retract intent
Barging
Occurs when new tasks get to execute before waiting tasks
barging avoidance: use of flag variable to ensure that barger does not execute ahead of waiting tasks
- barging still exists when the queue is empty
barging prevention: do not release lock when waking up a task
- change lock owner to new task
- barging does not occur
Hardware solutions to mutual exclusion
test and set
- starvation, no guarantee of eventual progress (rule 5)
- wait until returns OPEN
swap
- swap in dummy CLOSED value
- wait until new dummy is OPEN
fetch and increment
- returns value before incrementing
- wait until returns 0
- generalize to solve ticket counter problem
- ticket value overflow is not a problem as long as not all ticket values are simultaneously being used
- FIFO service \(\implies\) no starvation
6. Locks
Spin lock
Busy wait for event. Can yield the timeslice when check fails.
Most break rule 5, starvation.
6.4.3 Lock Techniques
split binary semaphore: collection of semaphores where at most 1 of them has the value 1
- essentially a binary semaphore, but across multiple distinct semaphores
- used when different kinds of tasks have to block separately
baton passing: used by split binary semaphores to pass the 1 value (conceptual baton) between component semaphores
- 3 rules of baton passing
- there is exactly 1 baton
- nobody moves in the entry/exit code unless they have the baton
- once the baton is released, cannot read/write variables in entry/exit
- implies no barging since baton is passed instead of released/acquired
- mutex/condlock can’t do baton passing since signalled task must implicitly re-acquire the lock
6.4.4 Readers and Writer Problem
- 2 types of tasks - readers and writers
- at any point, either allow multiple readers to read or 1 writer to write
- split binary semaphore sorts tasks into 3 pools: arrivers, readers, writers
7 solutions, each with a problem…
7. Concurrent Errors
7.1. Race Conditions
race condition: occurs when there is missing synchronization or mutual exclusion
7.2. No Progress
livelock: infinite postponement on simultaneous arrival
- infinite “you go first”
- takes up CPU cycles
- always exists a mechanism to break the livelock
- oracle with cardboard test – it should be possible to take away information from a task and have progress
starvation: selection algorithm ignores one or more tasks
- lack of long term fairness
- like livelock, starving task may switch between active, ready, and blocked
deadlock: one or more processes are waiting for an event that will not occur
- 5 conditions which must occur to get deadlock
- a concrete shared resource requiring mutual exclusion
- a process holds a resource while waiting for access to a resource held by another process (hold and wait)
- once a process has gained access to a resource, the runtime system cannot get it back (no preemption)
- there exists a circular wait of processes on resources
- the conditions must occur simultaneously
synchronization deadlock: failure in cooperation
uSemaphore s(0); // closed
s.P(); // wait infinitely
mutual exclusion deadlock: failure to acquire a resource protected by mutual exclusion
7.3. Deadlock Prevention
Eliminating one of the deadlock conditions \(\implies\) deadlock can never occur.
Synchronization Prevention
Eliminate all synchronization and communication, so tasks must be completely independent.
Mutual Exclusion Prevention
Deadlock rule removal analysis
- no mutal exclusion: impossible in many cases
- no hold and wait: do not give any resources unless all resources can be given
- poor resource utilization
- possible starvation
- allow preemption (dynamic, cannot be applied statically)
- no circular wait: use ordered resource policy
- complicated resource allocation procedures
- prevent simultaneous occurrence: show the rules can’t occur simultaneously
7.4 Deadlock Avoidance
Monitor all blocking and resource allocation to detect potential deadlock.
Achieves better resource utilization, but additional overhead required to avoid deadlock.
Banker’s Algorithm
Given a set of resources, can demonstrate a safe sequence of resource allocation which will not result in deadlock.
Processes need to state their maximum resource needs.
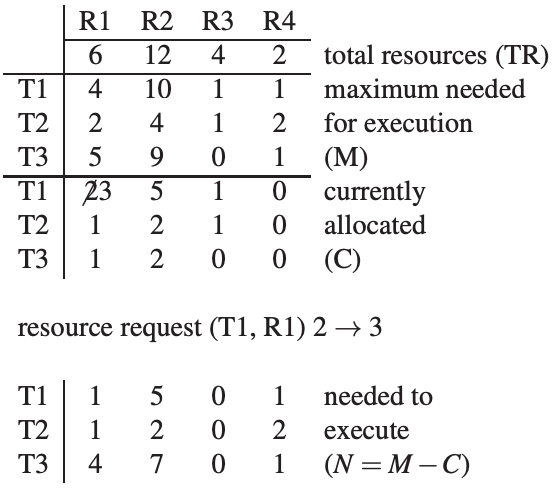

If there is a choice of next executing process, doesn’t matter which is chosen.
As long as a safe order exists, the Banker’s Algorithm allows the resource request.
Allocation Graphs
A bipartite graph of tasks and resources at each moment a resource is allocated.
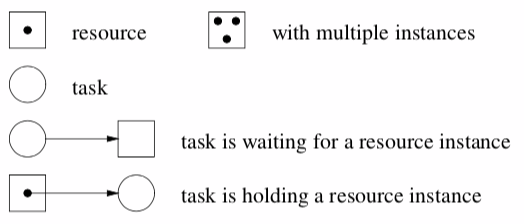
If each resource has one instance, cycle \(\implies\) deadlock.
Use graph reduction to locate deadlocks. Remove tasks that have only incoming arrow, essentially running the task to completion.
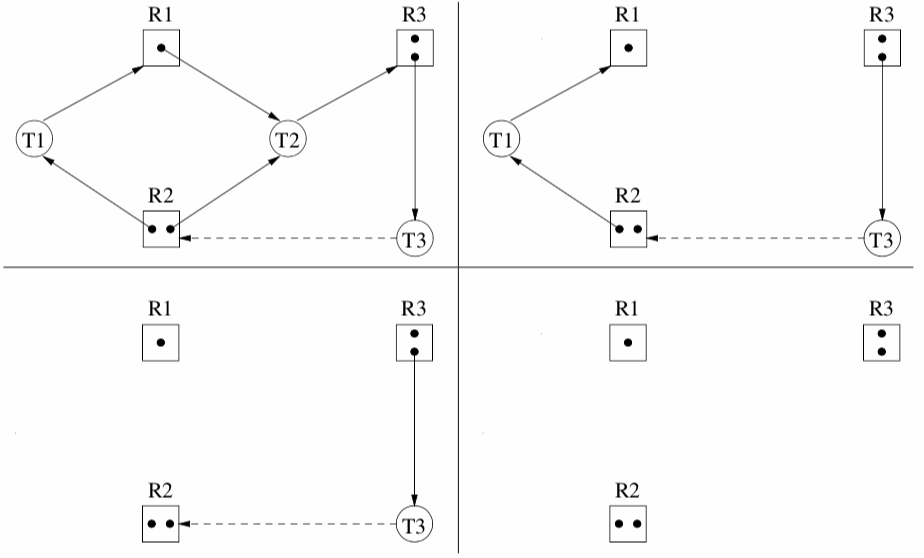
Problems:
- detecting cycle in large graph is expensive
- maybe be a large number of graphs to be examined, one for each allocation state
Detection and Recovery
To recover from deadlock, need:
- ability to discover deadlock
- ex. allocation graph: maybe run periodically or when a task needs to wait
- preemption
- choosing a victim is difficult and must prevent starvation
- victim must be restarted from beginning or a checkpoint
7.6. Which Method to Choose?
Of the techniques studied, only ordered resource policy has much practical value.
8. Indirect Communication
8.1. Critical Regions
VAR v : SHARED INTEGER
REGION v DO
// critical section
END REGION
Compiler helps to ensure region always closes and read/write only occurs in region.
If we allow reading outside the region, there may be reading partially updated information (readers-writer problem).
Nesting results in deadlock.
8.2. Conditional Critical Region
Use busy waiting to enter only if cond-expr is true. Could also use a wait queue.
REGION v DO
AWAIT cond-expr
...
END REGION
8.3. Monitor
monitor: ADT which combines shared data with serialization of its modification
mutex member: member routine which does not begin execution if there is another active mutex member
- queues of tasks waiting to enter a mutex member may form
- public member routines of a monitor are implicity mutex
- recursive entry via multi-acquisition lock
- implicit monitor lock release on unhandled exception
Destructor is mutex to allow threads in the monitor to finish.
8.4. Scheduling
Monitors may want to schedule task execution an order other than arrival order (ex. bounded buffer, r/w with stale/fresh).
External scheduling
Schedules tasks outside the monitor, accomplished with the accept statement.
accept controls which mutex members can accept calls, forming queues outside the monitor.
Acceptor task blocks until a call to a specified mutex member occurs. When the accepted mutex member exits or waits, the acceptor continues.
Unblocking (signalling) is implicit.
Cannot use external scheduling when:
- scheduling depends on task parameter values (ex. dating compatability code)
- scheduling must block in the monitor but cannot guarantee the next call fulfils cooperation
Internal scheduling
Allows tasks into the monitor, and then schedules them accordingly with condition variables and signal, wait.
condition is a queue of waiting tasks
uCondition x, y, z[5];emptyreturns true iff there are no tasks blocked on the queuefrontreturns an integer stored with the waiting taskwaitcalled by task to atomically put itself on the queue and releases the monitor locksignaldequeues a task and makes it ready- signalling task does not block, so signalled task waits for signaller to exit/wait
signalBlockblocks the signalling thread and unblocks the thread on the front of the queue
General model for monitor scheduling:
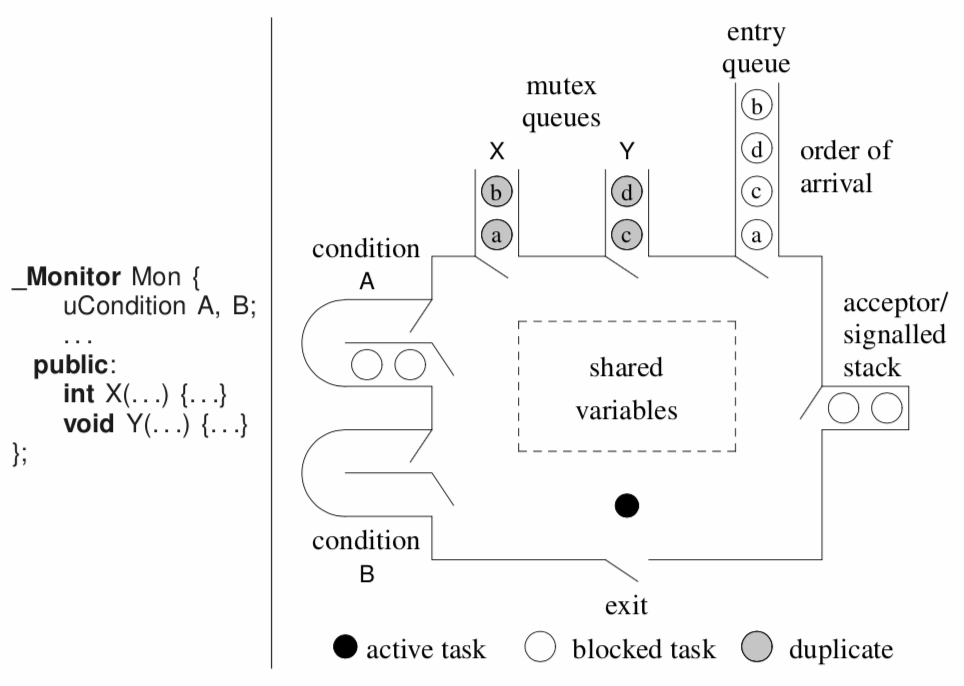
8.5. Readers/Writer with Monitor
Some modifications to the solutions from locks section…
nested monitor problem:
- acquire monitor lock \(M_1\)
- call to monitor \(M_2\)
- wait on condition in \(M_2\). This releases the \(M_2\) lock but not the \(M_1\) lock \(\implies\) hold and wait
8.6. Condition, Signal, Wait vs. Counting Semaphore, V, P
Differences:
- wait always blocks, P blocks only if semaphore = 0
- signal before wait is lost, V before P affects the P
- multiple Vs can start tasks simultaneously, multiple signals start tasks serially since each task exits serially through the monitor
8.7. Monitor Types
explicit scheduling occurs via
- internal scheduling by
signal - external scheduling by
accept
implicit scheduling occurs via monitor selects via wait/exit
Monitors classified by the implicit scheduling when a task waits/signals/exits.
Assign implicit scheduling priorities to the calling (C), signalled (W), and signaller (S) queues.
implicit/automatic signal monitor: no cv or explicit signal, use a waitUntil statement
- on monitor exit, wake up everything and recompute predicates (busy waiting)
- useful for prototyping monitors, but poor performance
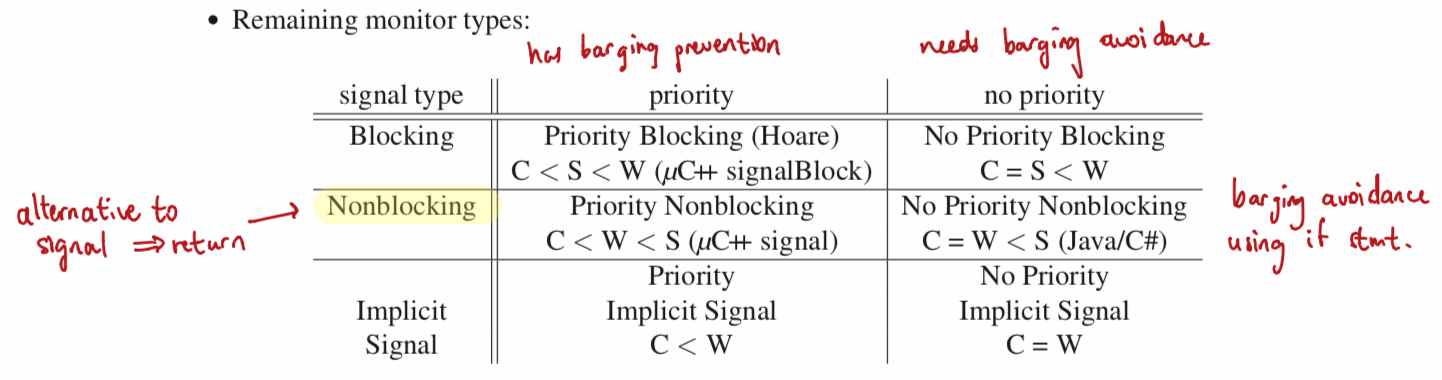
- no-priority blocking requires signaller task to recheck condition
- no-priority non-blocking requires signalled task to recheck condition
Coroutine monitor is a coroutine that can be used by multiple threads via its monitor features.
8.8. Java Monitor
Defined by synchronized class members.
All classes have one implicit condition variable, interact with wait, notify, notifyAll
Uses no-priority nonblocking.
Java has spurious wakeup, where blocked threads can randomly wake up to avoid deadlocks.
9. Direct Communication
Inter task communication through monitor is indirect and inefficient.
Instead, tasks can call each others’ member routines.
9.1. Task
Like a coroutine since it has distinguished member main, but different in that it has its own thread of control where execution starts.
Also like a monitor because of mutex members.
Execution properties produce different abstractions

9.2. Scheduling
Tasks can use external and internal scheduling like monitors do.
If an accepted mutex member ends via exception, it raises a RendezvousFailure at the acceptor (implicitly enabled).
If termination and deallocation follow one another, can end task by accepting the destructor. On destructor call, caller gets blocked and acceptor runs, allowing cleanup. Then the destructor can reactivate/wake up blocked tasks.
9.3. Increasing Concurrency
Possible in both client and server side.
9.3.1. Server Side
Client blocks in member, server does work and then unblocks client.
internal buffer has issues:
- unless average time of production and consumption is similar, the buffer is either always full or empty
administrator: server managing multiple clients are worker tasks
- does no work, mainly delegates
- always accepts calls
- doesn’t call other tasks in case of blocking, but may block itself
- worker: calls server to get work from buffer and returns results to buffer
- timer: prompt admin. at time interval
- notifier: perform potentially blocking wait for external event
- simple worker: do work and return result to admin.
- complex worker: do work and return result to client directly
- courier: perform a potentially blocking call on behalf of the admin.
9.3.2. Client Side
Asynchronous calls which don’t have to wait for completion.
Approach 1: 2 step protocol
- client makes separate
start(args)andwaitcalls and does work in between. - requires protocol so that correct result can be returned on
wait
Approach 2: Tickets
- same as 2 step protocol, but formalize the notion of a ticket to retrieve results
Approach 3: Callback Routine
- pass a non-blocking routine in initial call which is called by the server once it generates a result
- routine should set an indicator so that caller can poll for the result
- advantage: server can drop off result immediately instead of storing it in a buffer
Approach 4: Futures
- implicit protocol
- a future is immediately returned and is empty
- caller continues as if it was not empty
- server fills the future at some point in the future
- when the future is used, the caller may block waiting for it to become ready
- javascript promises?
Futures
Client side future operations
available: if the asynchronous call is completedoperator(): returns read-only future result- blocks if future is not available
- raises exception if server returns an exception
operator T: access after the future is known to be availablereset: make future as emptycancel: cancel the async call and unblocks waiting clientsuCancellationraised at clients still waiting
cancelled: check if cancelled
Server side future operations
delivery(T result): complete the async call and provide result, unblocks clientsexception(uBaseEvent * cause): return an exceptioncauseis automatically deleted by the future whenresetcalled or future is deleted
Complex Future Access
select statement: like an accept statement, but instead block on waiting for future(s) to become available
10. Optimization
General forms
- reordering: data and code reordered to increase performance
- eliding: removal of unnecessary data, data accesses, and computation
- replication: processors, memory, data, code are duplicated due to limitations in processing and communication speed
isomorphic: optimized program produces the same result as original program for fixed input